
Năm 2026, chúng ta đang chứng kiến một cuộc “lạm phát” thuật ngữ AI. Đi đâu cũng nghe về Agentic, về Autonomous, về “kỷ nguyên không cần con người”. Nhưng với tư cách là một Product Manager (PM) lăn lộn trong ngành Data, mình thấy nhiều doanh nghiệp đang ném tiền qua cửa sổ vì triển khai những hệ thống “overkill” (quá mức cần thiết) hoặc dùng sai mục đích.
Chọn sai kiến trúc không chỉ làm tốn chi phí Token, tăng Latency (độ trễ) mà còn khiến hệ thống kém ổn định trên môi trường Production. Bài viết này mình sẽ “mổ xẻ” chuyên sâu 4 cấp độ tiến hóa của AI từ góc nhìn Kỹ thuật hệ thống (System Thinking) để anh em biết rõ mình đang bỏ tiền mua cái gì.
1. LLM (Large Language Model): Tầng Tư duy xác suất & Bộ nhớ tham số

Mọi hệ thống AI hiện đại đều bắt đầu từ LLM (GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro). Đây là “bộ não” trung tâm.
-
Bản chất kỹ thuật: LLM hoạt động dựa trên Parametric Memory (Trọng số mạng thần kinh). Toàn bộ tri thức của nó được nén vào hàng tỷ tham số trong quá trình Pre-training. Nó không thực sự “biết” sự thật; nó chỉ dự đoán token tiếp theo có xác suất cao nhất dựa trên ngữ cảnh (Prompt).
-
Thông số cần quan tâm: Context Window (Cửa sổ ngữ cảnh) và Knowledge Cutoff.
-
Nỗi đau của Business: * Hallucination (Ảo giác): Khi dữ liệu trong trọng số không có (ví dụ: báo cáo nội bộ sáng nay), LLM sẽ tự “sáng tạo” để khớp với yêu cầu.
-
Tĩnh (Static): Nó không có khả năng cập nhật Real-time nếu không được can thiệp kỹ thuật.
-
-
Vibe: Giống như một ông giáo sư “biết tuốt” nhưng trí nhớ bị dừng lại ở 1 năm trước và cực kỳ bảo thủ khi gặp kiến thức mới.
2. RAG (Retrieval-Augmented Generation): Kiến trúc “Bộ nhớ ngoài” chuyên dụng

Để giải quyết bài toán “tin cậy”, chúng ta không Fine-tune LLM (vì quá đắt và chậm), chúng ta dùng RAG.
-
Bản chất kỹ thuật: Đây là sự kết hợp giữa Vector Database (Pinecone, Milvus, Weaviate) và LLM. Quy trình gồm 3 bước:
-
Ingestion: Chuyển dữ liệu (PDF, SQL, Doc) thành các Vector qua mô hình Embedding.
-
Retrieval: Khi user hỏi, hệ thống tìm kiếm Semantic Similarity (độ tương đồng ngữ nghĩa) để lấy ra Top-K đoạn văn liên quan nhất.
-
Generation: Đưa “sự thật” đó vào Prompt để LLM tổng hợp câu trả lời.
-
-
Góc nhìn chuyên môn: RAG giải quyết bài toán Grounding. Nó biến LLM từ một “kẻ nói dối chân thật” thành một “trợ lý tra cứu” có dẫn chứng.
-
Điểm yếu kỹ thuật: Nếu thuật toán Chunking (chia nhỏ văn bản) không tốt, AI sẽ bị mất ngữ cảnh (Lost in the Middle).
-
Vibe: Một thủ thư tận tâm, luôn cầm sẵn cuốn sách nghiệp vụ của công ty bạn trên tay trước khi trả lời.
3. AI Agent: Vòng lặp Suy luận (Reasoning) và Thực thi (Execution)

Đến tầng này, AI không chỉ còn là “máy nói”. Nó bắt đầu có Agency (năng lực hành động).
-
Bản chất kỹ thuật: Vận hành dựa trên khung tư duy ReAct (Reason + Act) kết hợp với Function Calling.
-
Thay vì trả lời ngay, Agent sẽ tự hỏi: “Tôi cần làm gì để đạt được mục tiêu này?”.
-
Nó có thể gọi các Tools: API thời tiết, Query SQL vào Database, chạy code Python trong Sandbox.
-
-
Khả năng đặc biệt: Self-Correction (Tự sửa lỗi). Nếu nó gọi API bị lỗi 404, nó sẽ tự suy nghĩ lại và thử một endpoint khác.
-
Nỗi đau kỹ thuật: Infinite Loops (vòng lặp vô tận) và Prompt Injection (rủi ro bảo mật khi AI tự ý gọi những hành động nhạy cảm).
-
Vibe: Một nhân viên thực tập thạo việc, biết dùng Google, biết dùng Excel và biết hỏi lại khi thấy có gì đó “sai sai”.
4. Agentic AI: Hệ sinh thái Đa tác tử (Multi-Agent Orchestration)
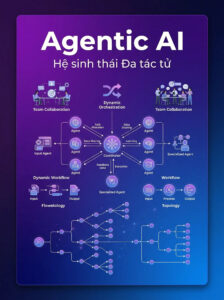
Đây là đỉnh cao mà các PM đang hướng tới trong năm 2026: Một hệ thống gồm nhiều Agent phối hợp như một phòng ban chuyên nghiệp.
-
Bản chất kỹ thuật: Sử dụng các Framework như CrewAI, Microsoft AutoGen hoặc LangGraph. Hệ thống được chia thành:
-
Manager Agent (Orchestrator): Chia nhỏ Task lớn (Decomposition) và phân việc.
-
Worker Agents: Các Agent chuyên biệt hóa (Researcher, Content Writer, Legal Reviewer).
-
Shared Memory: Một không gian lưu trữ ngữ cảnh chung để các Agent “trao đổi” với nhau.
-
-
Góc nhìn chuyên môn: Agentic AI mô phỏng cấu trúc SOP (Standard Operating Procedure) của doanh nghiệp. Nó không chạy một mạch từ đầu đến cuối mà có các bước kiểm soát chéo (Peer Review) giữa các Agent.
-
Hạn chế: Latency cực cao (đợi các Agent bàn bạc nhau) và chi phí Token tăng phi mã.
-
Vibe: Một đội ngũ Senior phối hợp nhịp nhàng, có quy trình phê duyệt, phản biện và nghiệm thu sản phẩm.
Bảng so sánh “Ma trận kỹ thuật” AI 2026
| Tiêu chí | LLM (Basic) | RAG (Knowledge) | AI Agent (Task) | Agentic AI (Process) |
| Logic lõi | Dự đoán Token | Tìm kiếm + Tổng hợp | Vòng lặp ReAct | Phối hợp đa tầng |
| Dữ liệu sử dụng | Tham số (Cũ) | Vector DB (Mới) | Tools + API | Toàn bộ hệ thống |
| Độ trễ (Latency) | Cực thấp | Thấp | Trung bình | Cao |
| Độ phức tạp | Thấp | Trung bình | Cao | Rất cao |
| Chi phí (Token) | $ | $$ | $$$ |
|
💡 Tư duy thiết kế hệ thống “Thực dụng”
Đừng để các Agency “lùa gà” bằng những từ khóa hào nhoáng. Khi bắt tay vào build sản phẩm, anh em hãy nhớ nguyên tắc của mình:
-
Nếu chỉ cần tra cứu thông tin chính xác: Hãy tối ưu RAG. Đừng cố build Agent tốn kém.
-
Nếu cần thực thi một Task cụ thể: Build AI Agent có bộ Tool mạnh (ví dụ: Data Analyst Agent).
-
Nếu cần tự động hóa một quy trình dài hơi (Marketing, Vận hành): Lúc đó mới đầu tư vào Agentic AI.
Năm 2026 rồi, đẳng cấp không nằm ở việc dùng công nghệ xịn nhất, mà nằm ở việc build được hệ thống ROI (Return on Investment) cao nhất. Dữ liệu là máu, AI là động cơ, nhưng anh em mới là người lái.
Anh em đang gặp khó khăn ở khâu nào? Cần mình phác thảo một Architecture Diagram cho hệ thống RAG chuẩn hay cần mình review một SOP cho Multi-Agent? Để lại comment bên dưới mình cùng mổ xẻ nhé!


