
Bias-Variance là khung tư duy cốt lõi giúp phân tích nguồn gốc sai số trong các hệ thống Machine Learning thực tế, đặc biệt trong các bài toán triển khai mô hình ngoài production.
Bản chất của Bias-Variance Decomposition trong Machine Learning thực tế
Bias-Variance Decomposition là một trong những khái niệm nền tảng quan trọng nhất trong Machine Learning mà bất kỳ ai học ML cũng từng gặp qua.
Error = Bias² + Variance + Noise
Tuy nhiên, trong thực tế làm Machine Learning, Bias-Variance Decomposition không phải là công thức để học thuộc, mà là khung tư duy để ra quyết định kỹ thuật.
Rất nhiều mô hình:
-
Đạt metric đẹp trong notebook
-
Validation score cao
-
Nhưng vẫn thất bại khi deploy
Lý do không nằm ở thuật toán, mà nằm ở cách chúng ta hiểu sai bias-variance.
Bias không phải “model quá đơn giản”

(Chú thích ảnh: Bias – sai lệch do giả định sai trong Machine Learning)
Một ngộ nhận phổ biến là:
Bias = model quá đơn giản
Thực tế, bias là sai lệch có hệ thống do giả định sai về thế giới.
Bias có thể xuất hiện ngay cả với model rất phức tạp.
Những nguồn bias phổ biến trong ML system
-
Linear model áp lên quan hệ phi tuyến → Model không đủ khả năng biểu diễn mối quan hệ thật
-
Loss function không phản ánh cost thực tế → Model tối ưu rất tốt nhưng decision sai
-
Feature thiếu thông tin quan trọng → Model bị giới hạn bởi dữ liệu đầu vào
👉 Điểm quan trọng: Bias đến từ formulation của bài toán, không chỉ từ kiến trúc model. Trong thực tế, rất nhiều bias được tạo ra ngay từ cách áp dụng Empirical Risk Minimization (ERM) – khi training loss không phản ánh đúng rủi ro và chi phí trong môi trường deployment.
Variance không chỉ là “overfitting”

(Chú thích ảnh: Variance – độ nhạy của mô hình với dữ liệu huấn luyện)
Variance thường bị đơn giản hóa thành:
Variance = model quá phức tạp → overfitting
Trong các hệ thống Machine Learning triển khai thực tế, variance phản ánh độ nhạy của model đối với dữ liệu huấn luyện.
Variance tăng cao khi:
-
Dữ liệu ít, noise lớn
-
Model có không gian giả thuyết rộng
-
Optimization tìm nghiệm khác nhau cho mỗi sample khác nhau
Variance không chỉ là vấn đề của model, mà là kết quả của data + training dynamics.
👉 Vì vậy:
-
Đổi model chưa chắc giảm variance
-
Thêm regularization chưa chắc giải quyết được gốc rễ
Deep Learning đã phá vỡ trực giác bias-variance cổ điển
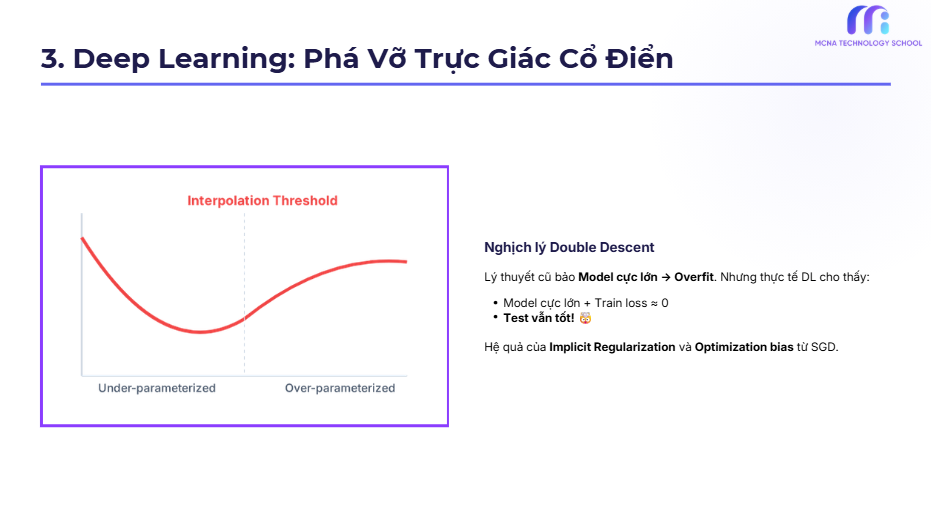
(Chú thích ảnh: Deep Learning và hiện tượng Double Descent)
Theo trực giác cổ điển:
Over-parameterized → variance cao → generalization kém
Nhưng Deep Learning lại cho thấy điều ngược lại:
-
Model cực lớn
-
Train loss ≈ 0
-
Test performance vẫn rất tốt
Hiện tượng này dẫn đến sự xuất hiện của các khái niệm:
-
📉 Double Descent
-
📐 Implicit Regularization
-
📊 Optimization bias của SGD
Bias-variance không biến mất, nhưng phân rã cổ điển không còn đủ để giải thích hành vi của deep model hiện đại.
Sai lầm nguy hiểm nhất khi áp dụng Bias-Variance trong Machine Learning

(Chú thích ảnh: Sai lầm phổ biến khi áp dụng bias-variance)
Những phản xạ quen thuộc nhưng nguy hiểm:
-
❌ “Model overfit → thêm regularization”
-
❌ “Variance cao → thêm data là xong”
Trong rất nhiều hệ thống production:
-
Thêm data → bias nặng hơn
-
Regularization → decision tệ hơn
-
Model đơn giản hơn → che giấu lỗi formulation
Khi đó, model có thể trông “ổn hơn”, nhưng hệ thống lại ra quyết định kém hơn.
Bias-Variance là công cụ chẩn đoán, không phải kết luận

(Chú thích ảnh: Bias-Variance là công cụ chẩn đoán, không phải kết luận)
Người làm Machine Learning giỏi không hỏi:
“Model này bias hay variance?”
Mà hỏi:
“Sai số này đến từ giả định nào của hệ thống?”
Bao gồm:
-
Giả định về phân phối dữ liệu
-
Giả định trong loss function
-
Giả định trong decision layer
Bias-variance chỉ là điểm khởi đầu để phân tích, không phải câu trả lời cuối cùng.
Khi hiểu đúng bias-variance, tư duy ML sẽ thay đổi
Khi nhìn bias-variance đúng bản chất, bạn sẽ:
-
Ít ám ảnh đổi model
-
Ít tin mù quáng vào accuracy
-
Tập trung nhiều hơn vào:
-
Formulation
-
Loss function
-
Decision layer
-
Cost và rủi ro thực tế
-
Đây cũng là ranh giới giữa:
-
ML trong notebook
-
Và ML trong hệ thống thực
Kết luận
Bias-Variance Decomposition trong Machine Learning không phải kiến thức học thuật để ghi nhớ, mà là khung tư duy để hiểu vì sao hệ thống Machine Learning sai.
Nếu không hiểu đúng bias-variance:
-
Model càng phức tạp → sai càng nhanh
-
Data càng nhiều → bias càng tinh vi nếu formulation hoặc loss function đặt sai
-
Metric càng đẹp → rủi ro càng khó kiểm soát
👉 Author: Duong Duy
👉 Để làm chủ tư duy đúng đắn và trang bị kỹ năng xây dựng mô hình thực chiến, bạn hãy tham khảo ngay lộ trình: Khóa học Python & Machine Learning – Từ Zero đến Hero tại MCNA.
🎓 MCNA Technology School – Tiên phong đào tạo ứng dụng AI, Big Data, Business Intelligence, Power BI, Python, SQL, Excel, VBA, RPA cho cá nhân và doanh nghiệp tại Việt Nam. 💼 Đối tác đào tạo của hơn 300+ doanh nghiệp lớn như: Viettel Global, Masan Group, Techcombank, VPBank, Daikin, VTV, VinUni, ĐH Ngoại Thương…
🌐 Tìm hiểu thêm:
-
Website: https://mcna.vn
-
Fanpage: facebook.com/mcnatechnologyschool
-
Group cộng đồng: facebook.com/groups/DataAnalyticsVietnam
-
YouTube: youtube.com/@mcna.technology.school
-
Linkedin: https://www.linkedin.com/company/mcna-vn
📞 Hotline: Tư vấn khóa học & doanh nghiệp: 0939.866.825 (Mr. Minh Khang)
🏢 Hệ thống cơ sở:
-
Cơ sở 01: 30 Trung Liệt, Đống Đa, Hà Nội
-
Cơ sở 02: Liền kề 44B, TT2, Khu đô thị Văn Quán, Hà Đông, Hà Nội
-
Cơ sở 03: The BIB Space, 50B Phan Tây Hồ, Phường Cầu Kiệu, HCMC
📌 Theo dõi MCNA để không bỏ lỡ các tài liệu, sự kiện & khóa học chuyên sâu về Data & AI.
Bài viết liên quan về Machine Learning
Để hiểu thêm bản chất và cốt lõi của Machine Learning, bạn có thể tham khảo: Bản chất Machine Learning là gì?
Để hiểu thêm về Empirical Risk Minimization (ERM), hãy tham khảo: ERM – Nền móng của Machine Learning


