
Learning Curve trong Machine Learning không chỉ dùng để phát hiện overfitting hay underfitting, mà là công cụ ra quyết định kỹ thuật quan trọng: nên thêm data, đổi model, làm feature engineering hay dừng lại vì formulation sai. Đọc sai learning curve là nguyên nhân phổ biến khiến dự án ML thất bại dù model và metric trông rất “đẹp”.
Chào mừng bạn đến với Ngày 5 của chuỗi series “30 ngày – Tư duy cốt lõi Machine Learning”.
Sau khi đã hiểu vì sao model có thể generalize trên dữ liệu chưa từng thấy ở Ngày 4, hôm nay chúng ta đi vào một công cụ thực chiến hơn: Learning Curve – nơi bạn không chỉ “quan sát” mô hình, mà phải ra quyết định đúng về data, model và formulation.
Vì sao Learning Curve thường bị hiểu sai?
Trong nhiều dự án Machine Learning, learning curve chỉ xuất hiện ở cuối pipeline:
-
Vẽ train loss và validation loss
-
Kiểm tra có overfit hay không
-
Đưa vào slide báo cáo cho “đủ bài”
Cách dùng này không sai, nhưng gần như vô dụng trong thực tế.
Bởi vì câu hỏi quan trọng nhất mà ML practitioner phải trả lời không phải là:
Model này có overfit không?
Mà là:
Từ learning curve này, quyết định hợp lý tiếp theo là gì?
Learning Curve thực chất đo lường điều gì?
Learning curve mô tả mối quan hệ giữa:
-
Lượng dữ liệu huấn luyện
-
Hiệu năng của model (training / validation)
Về bản chất, nó phản ánh sự cân bằng giữa:
-
Bias – sai số do giả định mô hình quá đơn giản
-
Variance – sai số do mô hình quá nhạy với dữ liệu
-
Noise – phần không thể học được từ dữ liệu
Do đó, learning curve không chỉ nói về model, mà còn nói về data, feature, loss function và formulation.
Learning Curve dùng để ra 4 quyết định quan trọng
1️⃣ Có nên thu thập thêm dữ liệu không?

-
Train ≈ Validation, cả hai đều cao
→ Thêm data không giải quyết được gốc rễ
→ Vấn đề nằm ở bias: feature yếu hoặc model không phù hợp -
Gap lớn, validation cải thiện khi thêm data
→ Data thực sự có giá trị
→ Thu thập thêm data là quyết định đúng
Sai lầm phổ biến là đổ tiền đi lấy data khi learning curve đã bão hòa.
2️⃣ Có nên dùng model phức tạp hơn không?

-
Train loss cao
→ Model chưa đủ capacity
→ Có thể tăng độ phức tạp -
Train rất thấp, validation kém
→ Model đã quá phức tạp
→ Thêm layer hay parameter chỉ làm variance tệ hơn
Learning curve giúp tránh việc “đắp deep learning” một cách mù quáng.
3️⃣ Có cần feature engineering không?
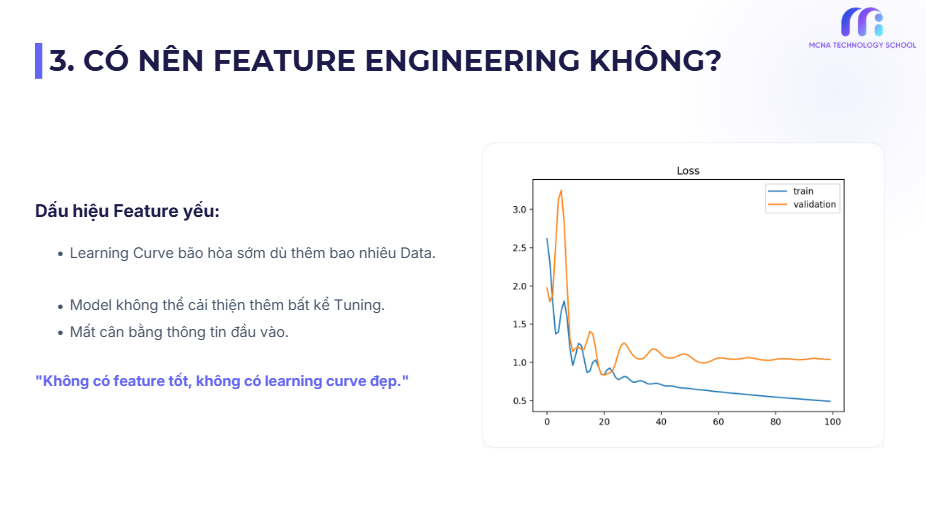
Một dấu hiệu rất thường gặp:
-
Learning curve cải thiện nhanh lúc đầu
-
Sau đó bão hòa sớm dù thêm data
Đây là dấu hiệu điển hình của feature representation kém.
Không có feature tốt, sẽ không bao giờ có learning curve đẹp – dù model có tinh vi đến đâu.
4️⃣ Có đang hiểu sai bài toán không?

Nếu:
-
Thêm data không cải thiện
-
Đổi model không cải thiện
-
Tuning hyperparameter không cải thiện
👉 Rất có thể bài toán đã bị formulation sai ngay từ đầu.
Lúc này:
-
Model phức tạp hơn chỉ che lỗi
-
Data nhiều hơn chỉ làm sai “đẹp” hơn
Learning Curve & Generalization: mối liên hệ cốt lõi
Nếu Generalization trả lời câu hỏi:
Vì sao model có thể hoạt động trên dữ liệu chưa từng thấy?
Thì Learning Curve trả lời câu hỏi khó hơn:
Khi model không generalize tốt, ta nên can thiệp ở đâu?
Learning curve chính là công cụ chẩn đoán thực nghiệm cho khả năng generalization.
Vì sao nhiều dự án ML thất bại vì Learning Curve?
Rất nhiều hệ thống ML thất bại không phải vì:
-
Thiếu thuật toán
-
Thiếu framework
-
Hay thiếu GPU
Mà vì:
-
Đọc sai learning curve
-
Can thiệp sai tầng (model thay vì data, tuning thay vì formulation)
-
Không hiểu learning curve phản ánh giả định nào đang bị phá vỡ
Kết luận
Learning curve không phải biểu đồ trang trí.
Nó là:
-
Công cụ ra quyết định
-
Bản đồ chẩn đoán lỗi
-
Và tấm gương phản chiếu tư duy Machine Learning của đội ngũ
Một ML practitioner giỏi không hỏi:
Model này tốt chưa?
Mà hỏi:
Từ learning curve này, quyết định tiếp theo hợp lý nhất là gì?
👉 Author: Duong Duy
👉 Để làm chủ tư duy đọc Learning Curve đúng cách, biết khi nào nên thêm data, đổi model hay dừng lại vì formulation sai, bạn có thể tham khảo lộ trình:
Khóa học Python & Machine Learning – Từ Zero đến Hero tại MCNA, tập trung vào xây dựng và đánh giá mô hình Machine Learning trong bối cảnh production thực tế.
🎓 MCNA Technology School – Tiên phong đào tạo ứng dụng AI, Big Data, Business Intelligence, Power BI, Python, SQL, Excel, VBA, RPA cho cá nhân và doanh nghiệp tại Việt Nam.
💼 Đối tác đào tạo của hơn 300+ doanh nghiệp lớn:
Viettel Global, Masan Group, Techcombank, VPBank, Daikin, VTV, VinUni, ĐH Ngoại Thương…
🌐 Tìm hiểu thêm:
Website: https://mcna.vn
Fanpage: facebook.com/mcnatechnologyschool
Group cộng đồng: facebook.com/groups/DataAnalyticsVietnam
YouTube: youtube.com/@mcna.technology.school
LinkedIn: https://www.linkedin.com/company/mcna-vn
📞 Hotline:
Tư vấn khóa học & doanh nghiệp: 0939.866.825 (Mr. Minh Khang)
🏢 Hệ thống cơ sở:
Cơ sở 01: 30 Trung Liệt, Đống Đa, Hà Nội
Cơ sở 02: Liền kề 44B, TT2, Khu đô thị Văn Quán, Hà Đông, Hà Nội
Cơ sở 03: The BIB Space, 50B Phan Tây Hồ, Phường Cầu Kiệu, HCMC
📌 Theo dõi MCNA để không bỏ lỡ các tài liệu, sự kiện & khóa học chuyên sâu về Data & AI.
🔗 Bài viết liên quan
-
Generalization trong Machine Learning: Generalization trong Machine Learning là gì?
-
Bias–Variance Decomposition: Bias-Variance Decomposition: Công thức ai cũng học, nhưng tất ít người dùng đúng
-
Empirical Risk Minimization & giới hạn trong production: ERM – Nền móng của Machine Learning


